こんにちは、今回はdrop関数に関して詳しくまとめていきたいと思います。
DataFrameの整形で非常に役に立つ関数なのでぜひ使い来ないしたいですね。
特に、dropを使ったのに削除できなかったときの対処法も書いています。

行・列の削除に使える関数
| 関数 | 処理 |
|---|---|
| df.pop(列名) | 1列を削除する |
| del df[列名] | 複数列を削除できる。df.loc[行名]は使えない |
| df.drop() | 複数行・列を削除できる この記事で解説します。 |
| df.dropna() | NaNのセルがある行・列を削除 【関連記事】dropnaの使い方まとめ |
| df.drop_duplicates() | 重複列の削除 【関連記事】drop_duplicatesまとめ |
pop、del、dropの3つの基本的な使い方は以下の記事でまとめています。
こんにちは、今回はpandasのDataFrameで行や列を削除する方法を解説していきます。 それぞれの役割やメリットを確認しながら基本的なポイントを押さえていきましょう。 [itemlink post_id="4429"] […]

今回はdrop関数についてみていきましょう。
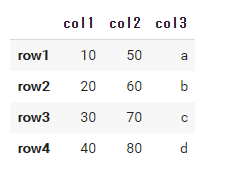
以下では次のDataFrameに対して処理を行っていきます。
このコードはGoogle Colaboratoryやjupyter notebook、jupyter lab上で実行できます。
|
1 2 3 4 5 6 7 8 9 10 |
import pandas as pd df = pd.DataFrame( data={'col1': [10, 20, 30, 40], 'col2': [50, 60, 70, 80], 'col3': ['a', 'b', 'c', 'd']}, index=['row1', 'row2', 'row3', 'row4'] ) df |
drop関数の引数
| dropの引数 | 引数のデフォルト値 | 詳細 |
|---|---|---|
| labels | None | 削除したい行名か列名(複数ならリスト) 行名と列名の混同はできない。 |
| axis | 0(行方向) | 1で列方向 |
| index | None | 行名の文字列(複数行ならリスト) |
| columns | None | 列名(複数列ならリスト) |
| level | None | マルチインデックスのDataFrameに対して使う |
| inplace | False | TrueでもとのDataFrameを変更する |
| errors | 'raise' | 'ignore'にするとlabelsに存在しな行名や列名を渡しても自動的にスルーしてくれる |
labels、axis、index、columnsの使い方は以下の記事でまとめているので、
今回は簡単に紹介するにとどめます。
こんにちは、今回はpandasのDataFrameで行や列を削除する方法を解説していきます。 それぞれの役割やメリットを確認しながら基本的なポイントを押さえていきましょう。 [itemlink post_id="4429"] […]
drop関数の基本的な使い方
列の削除
列を削除するにはcolumnsに列名を渡すか、axis(軸)に1を渡します。
また、複数列を削除するならリストを使いましょう。
以下のコードは列col1を削除する方法を2通りで書いています。
|
1 2 3 4 5 |
#①columnsを指定する方法 df.drop(columns='col1') #②軸(axis)を指定する方法 df.drop('col1', axis=1) |

行の削除
行を削除するにはindexに行名を渡すか、axis(軸)に0を渡します。
複数行を削除するならリストを使いましょう。
以下のコードはrow1、row2を削除する方法を3通りで書いています。
|
1 2 3 4 5 6 7 8 |
#①indexを指定する df.drop(index=['row1', 'row2']) #②軸(axis)を指定する df.drop(['row1', 'row2'], axis=0) #③行はaxisを省略可能 df.drop(['row1', 'row2']) |
inplaceの役割と消えない理由・対策
inplace=False(デフォルト)のとき
このとき元のDataFrameは変更されずに、行や列を削除したコピーのDataFrameが返されます。
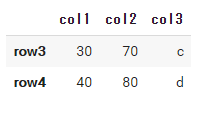
以下のように列col1を削除後にdfを表示させると、変更前のDataFrameが表示されます。
|
1 2 |
df.drop('col1', axis=1) df #もとのdfが表示される |
このように、せっかく行や列を削除してもその変更が維持されなければ意味がないですよね。
こういった戻り値のことを知らないと、「行や列が消えない!」なんてことになって変なところで足止めを食らう可能性もあります。そこで2つの対策方法を紹介します。
対策①新たな変数に代入する
もとのDataFrameはそのまま残しておきたいときは、
次のように新たな変数に代入してあげた方がいいですね。
|
1 2 |
df_d = df.drop('col1', axis=1) df_d |
対策②inplace=Trueに変更
もとのDataFrameを残しておく必要がないときは、
「inplace=True」に変更することで解決します。
|
1 2 |
df.drop('col1', axis=1, inplace=True) df #削除されたdfが表示される |
levelの使い方
マルチインデックス(MultiIndex)のDataFrameを削除するときに使えます。
マルチインデックスとは以下のような構造のDataFrameのことです。
|
1 2 3 4 5 6 7 8 9 |
midx = pd.MultiIndex(levels=[['Mult1', 'Mult2', 'Mult3'], ['row1', 'row2', 'row3']], codes=[[0, 0, 0, 1, 1, 1, 2, 2, 2], [0, 1, 2, 0, 1, 2, 0, 1, 2]]) df = pd.DataFrame(index=midx, data={'col1': [1, 2, 3, 4, 5, 6, 7, 8, 9], 'col2': [10, 20, 30, 40, 50, 60, 70, 80, 90], 'col3': [11, 22, 33, 44, 55, 66, 77, 88, 99]}) df |
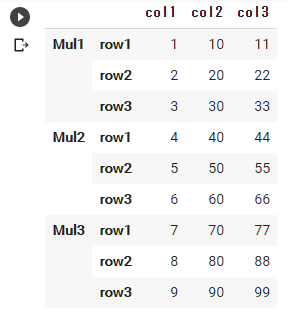
indexを2段階で設定しているイメージですね。
詳しい書き方などは別記事で解説したいと思います。
これに対してdropを使うと以下のようになります。
|
1 2 3 4 5 6 7 8 9 10 11 |
#①外側のindexを削除 df_mul.drop(index='Mul2') #②内側のindexを削除するにはlevel=1にする df_mul.drop(index='row1', level=1) #③levelがないとエラー df_mul.drop(index='row1') #③の出力結果 KeyError: 'row1' |

外側のindexを指定するときにlevelは必要ありませんが、
内側のindexを削除するときには必要です。
errorsの使い方
- errors=’raise’(デフォルト)
- 存在しない行名・列名を渡すとエラーになる。
- errors=’ignore’
- 存在しない行名・列名はスルーしてくれる。
|
1 2 3 4 5 |
#row5は存在しない df.drop(index=['row1', 'row2', 'row5']) #出力結果 KeyError: "['row5'] not found in axis" |
|
1 2 |
#row5はスルーしてくれる df.drop(index=['row1', 'row2', 'row5'], errors='ignore') |
必要のないエラーをカットできるので便利ですが、本当は削除したいのにスペルミスで入力してしまったときもスルーされてしまうので乱用は避けたいですね。人間が入力するときではなく、プログラムからプログラムに渡すときに使用することをおススメします。
まとめ
いかがでしたか。今回はdropについて詳しくまとめていきました。
たくさん引数がありますが、それぞれの役割を分かって使うととっても便利になりますね。