データ分析には欠かせないライブラリはたくさんありますね。
今回はその中でも表を使ってデータの加工ができるpandasについてみていきましょう。
この記事では以下の3つのポイントをまとめています。
- pandasとは?何ができるの?
- インストール方法は?
- 基本的な使い方とブロードキャスト機能の解説
初めてpandasを触る人向けの記事になっています。

pandasとは?
- pandasとはデータ加工・分析に特化したライブラリのことです。
- 基本的にはDataFrameやSeriesと言われる表を使ってデータを加工していく。
DataFrameはExcelのような表みたいなものという認識でOKです。
Series(シリーズ)は1列だけのDataFrameのことです。
「データの加工」と言われてもピンとこないかもしれないですが、「データの形式をそろえたり、データの傾向をみること」だと考えておきましょう。
実際のデータは、文字列と数値が混ざっていたり、異なる単位で記録されていたり、人間が書いたコメントがあったりと様々です。
そういったデータを見やすくしたり、不要な部分を削ったりするのがpandasの役割です。
そのほかにも、平均や標準偏差などの統計量を出すこともできます。
plotlyという可視化ライブラリーを使うとグラフにすることもできます。
Pythonでグラフを描くときに便利なplotlyですが、初心者にとっては難しいかもしれないですね。 私も初めて使ったときは何が何だかサッパリでしたが、理解できるとサクサクグラフを描くことができます。 今回は初心者向けにplo[…]

ほかにもNumpyという数値計算に特化したライブラリとも相性がいいのでよく使われています。
インストールとインポート方法
インストール方法
|
1 2 3 4 5 |
#コンソールの場合 $ pip install pandas #Anacondaの場合 conda install pandas |
ほかのライブラリと同様に一行でインストール完了です。
完了後に「pip list」や「conda list」とするとインストールされたライブラリ一覧が表示されるので、その中にpandasがあればOKです。
インポートのポイント
|
1 |
import pandas as pd |
インポートの手順もほかのライブラリと同じです。
pandasの場合は「as pd」として利用します。

pandasの基本操作
データフレームの作成
pandasの基本はDataFrameという表の操作になります。
以下のようにDataFrameを作ることができます。
|
1 2 3 4 5 6 7 |
df1 = pd.DataFrame( data={'列1': [10, 20, 30, 40], '列2': [50, 60, 70, 80], '列3': ['a', 'b', 'c', 'd']} ) df1 |
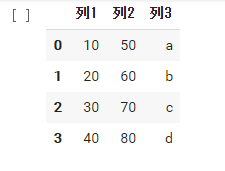
上のような表をDataFrameと言います。特に1列だけのものをSeries(シリーズ)と言います。
表の大きさが異なるだけで同じように扱うことができます。
他にもDataFrameのつくり方はたくさんあります。詳しくは以下の記事でまとめています。
データ分析ではPythonのpandasが有名ですよね。とくに大量のデータを処理できるデータフレーム(DataFrame)は使いこなせると便利です。 そこで今回は、データフレームの作成方法を紹介していきたいと思います。 [it[…]

行や列の抽出
データフレームは行や列の単位で扱います。
辞書のように列名を渡してあげるとその列を取り出すことができます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
#列の抽出 df1['列1'] ##出力結果 0 10 1 20 2 30 3 40 Name: 列1, dtype: int64 #行の抽出 df1.iloc[1] ##出力結果 列1 20 列2 60 列3 b Name: 1, dtype: object |
このように行や列を取り出すことを抽出と言います。
抽出の詳しい方法は以下の記事でまとめています。
今回はデータフレームで行・列・要素を指定して取得する方法をまとめてみました。 主な方法は4つ「loc・iloc・at・iat」です。 それぞれでできることやできないことがあるので一つ一つ見ていきましょう。 今回は以下のデ[…]

行や列の計算
抽出した列や行に対して計算することができます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
#かけ算 df1['列1']*3 ##出力結果 0 30 1 60 2 90 3 120 Name: 列1, dtype: int64 #足し算 df1['列1'] + df1['列2'] ##出力結果 0 60 1 80 2 100 3 120 dtype: int64 |
計算するときはデータ型が一致していないとできません。数値に見えても文字列扱いになっている場合があるので注意しましょう。
ブロードキャストとは?
- ブロードキャスト機能
- 要素同士を計算してくれる機能のこと。Numpyの配列にもこの機能がある。Pythonのリストにはない機能。
先ほどの行や列の計算ではかけ算と足し算を行いました。
計算結果を見ても分かる通り、各要素が3倍されていたり、各要素同士が足されています。
この機能がブロードキャストと呼ばれるものです。
Pythonのリストと比較するとわかりやすいので以下の例と比べてみましょう。
|
1 2 3 4 5 6 7 8 |
#リストの場合 print([1, 2, 3]*3) print([1, 2, 3]+[1, 2, 3]) ##出力結果 [1, 2, 3, 1, 2, 3, 1, 2, 3] [1, 2, 3, 1, 2, 3] |
リストに3をかけると長さが3倍になっていますし、足し算するとリストが結合されます。
このようにリストでは要素同士が計算されないのでデータ分析には不向きですが、pandasのDataFrameでは要素同士の計算を得意としています。
実際にデータ解析をしているときにこの機能を意識することはありませんが、Numpyの配列にも備わっている機能なので理解してると応用が利くかもしれないでですね。
まとめ
いかがでしたか?
今回はpandasに関して以下のことをまとめてみました。
- pandasはデータ分析に特化したライブラリ
- DataFrameは列や行単位で扱う
- ブロードキャスト機能があるので計算が楽!
- csvやExcelなどから読み込み、出力できる
- 可視化ライブラリのplotlyを使うと簡単にグラフがつくれる
データ分析用のライブラリと聞くと大げさに聞こえるかもしれないですが、やっていることは表の計算です。
ですが、たくさんの機能が備わっています。当サイトでもいろいろまとめています。
参考になれば幸いです。