csvをDataFrameとして読み込むときに日付の処理ができると便利ですよね。
この記事では、Pythonのpandasでread_csv関数の日付に関する処理を紹介してきます。
ほかのread_csv関数の引数は以下の記事にまとめています。
pandasでcsvをDataFrameとして読み込めるととっても便利ですよね。 ですが、ただ読み込むだけでなく、indexや読み込む行列を指定したり、欠損値を処理したりいろんなことができるとなお便利です。 そこで、この記事で[…]


日付処理に使う引数
| 引数 | デフォルト値 | 意味 |
|---|---|---|
parse_dates | False | True:indexの解析(indexが日付のときのみ機能します。) 列名のリスト:各列を日付データとして解析 列名のリストのリスト:結合して日付として解析 |
infer_datetime_format | False | Trueのときparse_datesも有効なら処理速度が向上する可能性がある。 |
keep_date_col | False | Trueのときparse_datesが複数列の結合を指定しているなら、元の列を削除しない。 |
date_parser | None | 日付データを処理する関数を渡す。あらかじめ関数を定義しておく必要あり。 |
dayfirst | False | Trueにすると、日ー月の順になっているデータも読み込める。 |
cache_dates | True | Trueなら一意に変換された日付のキャッシュを使用して、日付時間の変換を行う。 |
今回はこれらの引数を解説していきます。
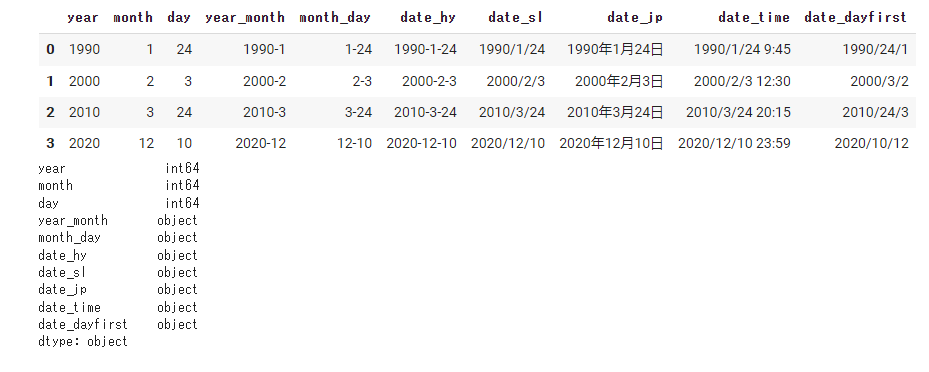
解説には以下のcsvファイルを使います。
|
1 2 3 4 5 |
path = 'https://www.self-study-blog.com/wp-content/uploads/2021/10/sample_date.csv' data = pd.read_csv(path, encoding='utf-8') display(data) print(data.dtypes) |
parser_datesの使い方
parser_dates=True:indexが日付ならdatetimeに変換parser_dates=['列名','列名']:指定した列をdatetimeに変換parser_dates=[['列名','列名']]:指定した列を結合してdatetimeに変換- 結合したい列をリストに入れる。
- 結合した元の列は削除される。
keep_ate_col=Trueでもとの列は削除されない。
parser_dates={'新列名': ['列名','列名']}:結合した列名を新列名に変更
①indexの日付をdatetimeに変換する
|
1 2 3 4 5 6 7 |
#①indexの日付をdatetimeにする。 data = pd.read_csv(path, encoding='utf-8', index_col='date_hy', parse_dates=True) display(data) print(data.index) |
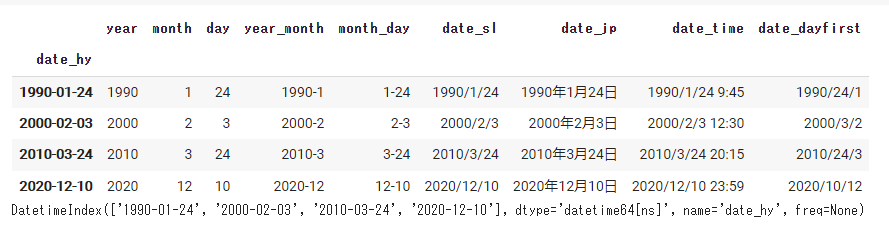
indexに日付が設定されているときにのみ機能します。
index_colを使用するとMultiindexになるので注意が必要です。
②指定した列をdatetimeに変換する
|
1 2 3 4 5 6 7 |
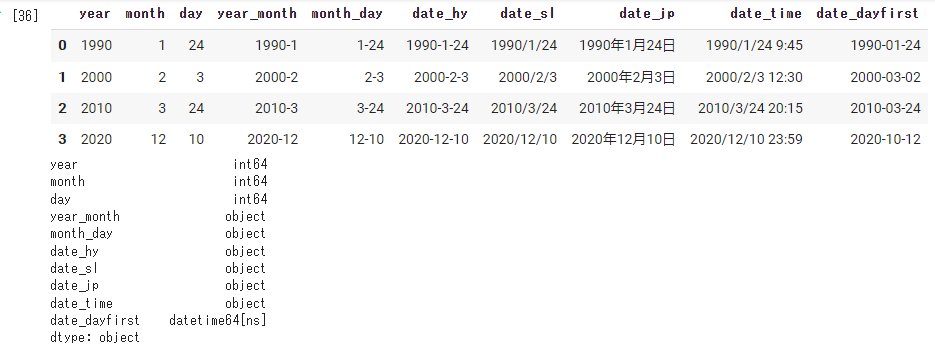
#②指定した列をdatetimeにする。 data = pd.read_csv( path, encoding='utf-8', parse_dates=['year', 'month', 'day', 'year_month', 'month_day', 'date_hy', 'date_sl', 'date_jp', 'date_time', 'date_dayfirst']) display(data) print(data.dtypes) |
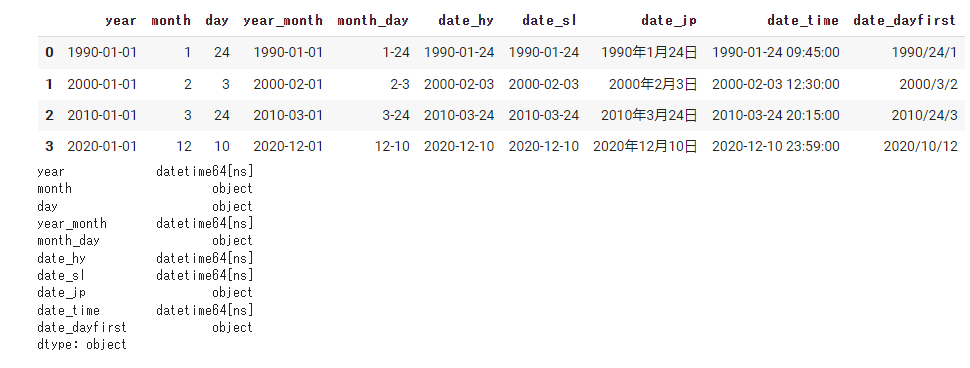
年のデータがある列(year、year_monthなど)はdatetimeに変換されますが、monthとdayのみの列は変換されません。
year列の月日は自動的に1月1日で処理されています。
また、日本語表記(○○年〇月〇日)はdatetimeにはなりません。
一番右の列のように日→月の順のときは以下のようにdayfirstを使うと処理できます。
|
1 2 3 4 5 6 7 |
#②日→月の順になっているときはdayfirstを使う。 data = pd.read_csv(path, encoding='utf-8', parse_dates=['date_dayfirst'], dayfirst=True) display(data) print(data.dtypes) |
③複数列を結合してdatetimeに変換する
|
1 2 3 4 5 6 |
#③複数列を結合してdatetimeに変換する。 data = pd.read_csv(path, encoding='utf-8', parse_dates=[['year', 'month', 'day']]) display(data) print(data.dtypes) |
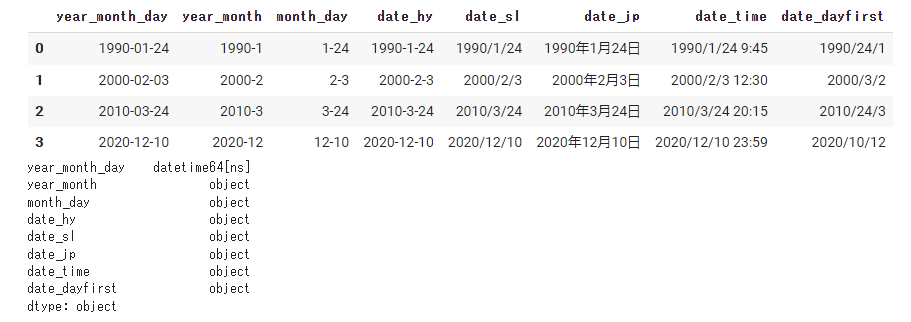
複数列を結合することで日付をまとめて処理できます。
このとき元の列は削除されますが、残しておく場合は以下のようにkeep_date_colを使います。
元の列を削除しない
|
1 2 3 4 5 6 7 |
#元の列を削除しないときはkeep_date_colを使う。 data = pd.read_csv(path, encoding='utf-8', parse_dates=[['year', 'month', 'day']], keep_date_col=True) display(data) print(data.dtypes) |
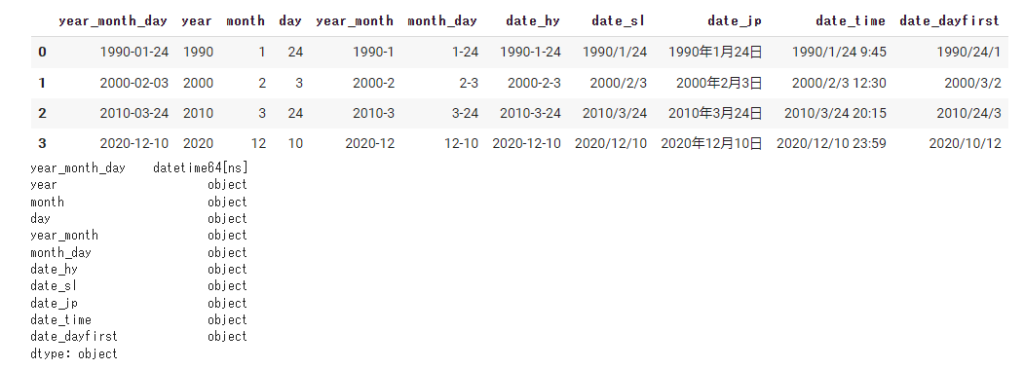
結合された列名は自動的に決まりますが変更したい場合は以下のようにdictで渡しましょう。
④結合した列名を変更する
|
1 2 3 4 5 6 7 |
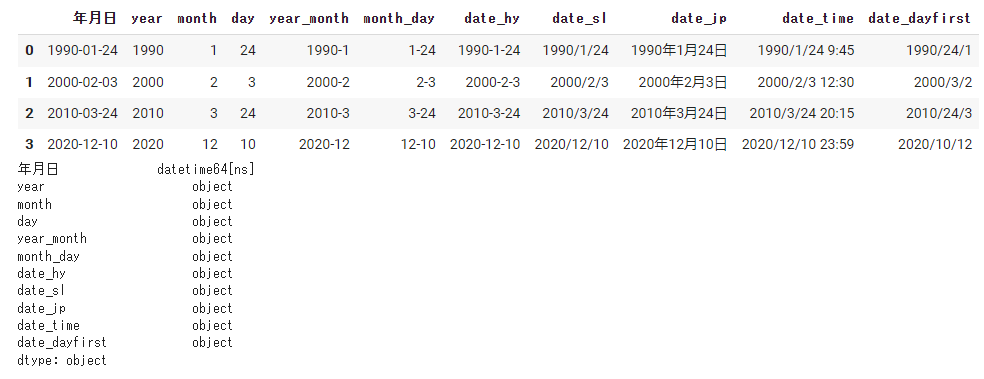
#➃結合した列名を変更する。 data = pd.read_csv(path, encoding='utf-8', parse_dates={'年月日': ['year', 'month', 'day']}, keep_date_col=True) display(data) print(data.dtypes) |
date_parserの使い方
日付のフォーマットを決めるときに使います。
以下のような関数を使うと日本語表記の日付も処理できます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
#先に日付処理の関数を定義しておく。 def jp2date(x): #日本語フォーマットの日付をdatetimeに変換 from datetime import datetime return datetime.strptime(x, '%Y年%m月%d日') data = pd.read_csv(path, encoding='utf-8', parse_dates=['date_jp'], date_parser=jp2date, #関数名を渡す ) display(data) print(data.dtypes) |
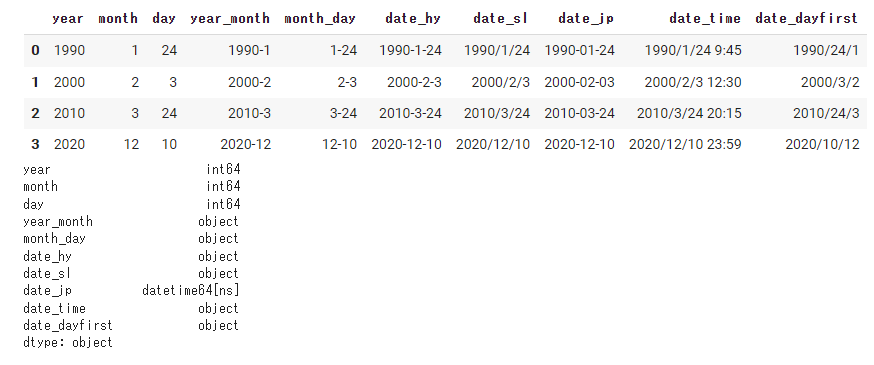
また、以下のように日本語表記にすることも可能ですが、datetimeに変換されません。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
#先に日付処理の関数を定義しておく。 def date2jp(x): #日本語のフォーマットで表示する from datetime import datetime return datetime.strptime(x, '%Y-%m-%d').strftime('%Y年%m月%d日') data = pd.read_csv(path, encoding='utf-8', parse_dates=['date_hy'], date_parser=date2jp, #関数名を渡す。 ) display(data) print(data.dtypes) |
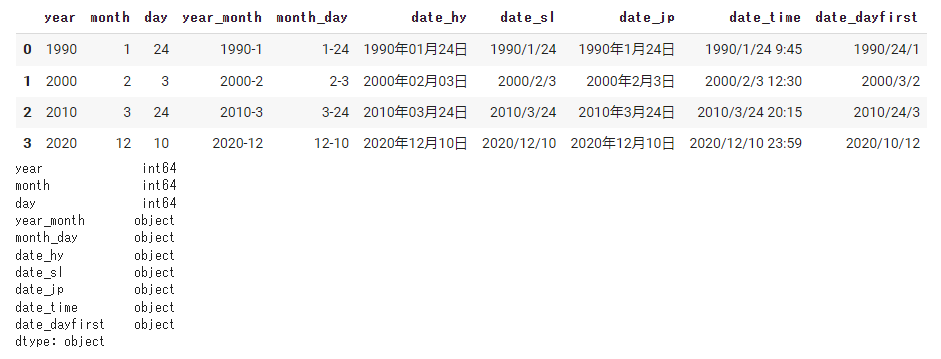
まとめ
今回はread_csv関数の日付を処理する方法を見ていきました。
関数を指定して処理できるのでいろんなことができると思います。
参考になれば幸いです。