今回はDataFrameの行や列を追加・削除する方法を紹介します。リストや配列、Seriesを使うことで可能になります。
DataFrameの作成方法は以下の記事をご覧ください
関連記事
データ分析ではPythonのpandasが有名ですよね。とくに大量のデータを処理できるデータフレーム(DataFrame)は使いこなせると便利です。 そこで今回は、データフレームの作成方法を紹介していきたいと思います。 [it[…]


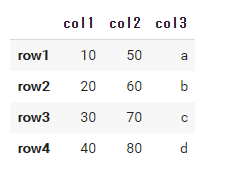
以下では次のDataFrameに対して処理を行っていきます。このコードはGoogle Colaboratoryやjupyter notebook、jupyter lab上で実行できます。
|
1 2 3 4 5 6 7 8 |
df = pd.DataFrame( data={'col1': [10, 20, 30, 40], 'col2': [50, 60, 70, 80], 'col3': ['a', 'b', 'c', 'd']}, index=['row1', 'row2', 'row3', 'row4'] ) df |

行・列の追加
列を末尾に追加
- 列名を指定する
- 全行に同じ値を追加できる
- リストや配列は行数と同じ長さにする
- Seriesはindexを指定すると好きな行に追加できる
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
#すべての列に同じ値 df['col4'] = 100 #すべての列を空に df['col5'] = np.nan #リストで追加 df['col6'] = [0.11, 0.12, 0.13, 0.14] #配列で追加 df['col7'] = np.array([0.21, 0.22, 0.23, 0.24]) #Seriesで追加 df['col8'] = pd.Series([0.31, 0.32, 0.33], index=['row1', 'row2', 'row4']) #列同士の和 df['col9'] = df['col1'] + df['col2'] df |
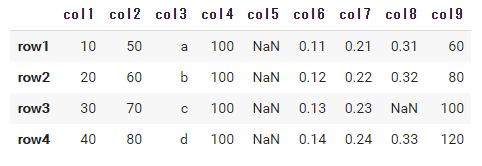
9列目のように1列目と2列目の値の和を追加することも可能です。
行を末尾に追加
- .locメソッドを使って行名を指定する
- 全行に同じ値を追加できる
- リストや配列は列数と同じ長さにする
- Seriesはindexを指定すると好きな列に追加できる
列に追加するときも、行に追加するときもSeriesを使う場合はindex引数で場所を指定します。column引数はありません。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
#すべての行に同じ値 df.loc['row5'] = 100 #すべての行を空に df.loc['row6'] = np.nan #リストで追加 df.loc['row7'] = [0.11, 0.12, 0.13] #配列で追加 df.loc['row8'] = np.array([0.21, 0.22, 0.23]) #Seriesで追加 df.loc['row8'] = pd.Series([0.32, 0.33], index=['col2', 'col3']) #行同士の和 df.loc['row9'] = df.loc['row1'] + df.loc['row2'] df |
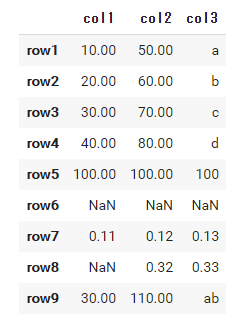
9行目のように1行目と2行目の和を考えることも可能です。このときデータ型は自動で処理されます。1,2列の和はfloat(小数)で計算されて、30.00、110.00となていますが、3列目はstr文字列の和なのでabと結合されています。
今回は和なので数値でも文字列でも処理できましたが、一般にデータ型が異なる場合は他の演算(差・商・積)を行うとエラーになるので注意が必要です。
DataFrameのデータ型に関する記事は近日公開予定です。
まとめ
いかがでしたか?
今回はDataFrameに行や列を追加する方法を紹介しました。基本的には行名や列名を指定してリストや配列を渡してあげると完結ですね
特に、Seriesでindexを指定すると特定の場所に要素を追加できるので便利ですから覚えておきたいですね。