今回はDataFrameの重複した行の削除に使う関数の解説です。
コードと画像をたくさん使っています。参考になれば幸いです。

行・列の削除に使える関数
| 関数 | 処理 |
|---|---|
df.pop(列名) | 1列を削除する |
del df[列名] | 複数列を削除できる。df.loc[行名]は使えない |
df.drop() | 複数行・列を削除できる 詳しくはコチラの記事へ |
df.dropna() | NaNのセルがある行・列を削除 詳しくはコチラの記事へ |
df.drop_duplicates() | 重複列の削除 この記事で解説します。 |
pop、del、dropの3つの基本的な使い方は以下の記事でまとめています。
こんにちは、今回はpandasのDataFrameで行や列を削除する方法を解説していきます。 それぞれの役割やメリットを確認しながら基本的なポイントを押さえていきましょう。 [itemlink post_id="4429"] […]

この記事ではdrop_duplicates関数に関して解説していきます。
drop_duplicates関数の引数
| 引数 | デフォルト値 | 処理 |
|---|---|---|
subset | 全ての列 | 指定した列で重複した行を削除 |
keep | 'first' | 'first'は 重複行の最初を残す 'last'は重複行の最後を残すFalseは重複行をすべて削除 |
ignore_index | False | Trueでindexを0からに変更する |
inplace | False | TrueでもとのDataFrameを変更する |
それぞれの引数の解説では以下のデータフレームを使います。
|
1 2 3 4 5 6 7 8 9 10 11 |
import pandas as pd df = pd.DataFrame( {'name': ['Tom', 'Tom', 'tom', 'Ken', 'Bob', 'Ken'], 'class': ['A', 'A', 'A', 'B', 'B', 'B'], 'height': [170, 170, 170, 180, 190, 180], 'weight': [75, 75, 68, 80, 80, 80], 'address': ['USA', 'USA', 'USA', 'USA', 'usa', 'USA']}, index=[1, 2, 3, 4, 5, 6]) df |
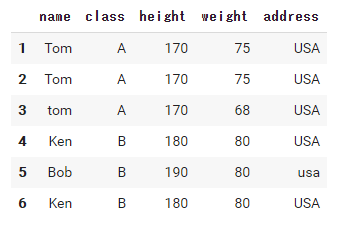
drop_duplicates関数は、重複している行を削除するものです。
もし重複している列を削除したい場合は転置すると行として同じように処理できます。
subsetの役割
- デフォルトですべての列が重複している行を削除する。
subset='列名'または、列名のリストを渡す。
デフォルト(すべての列が重複する行を削除)
|
1 |
df.drop_duplicates() |
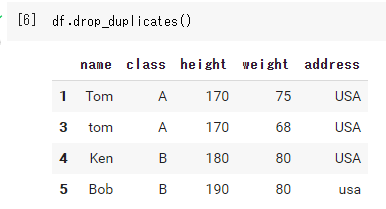
文字列の大文字と小文字は区別されるので注意が必要です。
特定の列が重複する行を削除
|
1 |
df.drop_duplicates(subset='class') |
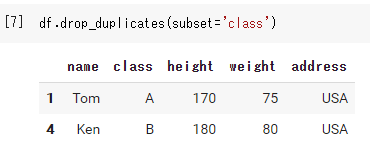
もし、複数の列の重複を削除したい場合は以下のように列名のリストを渡しましょう。
|
1 |
df.drop_duplicates(subset=['class', 'address']) |
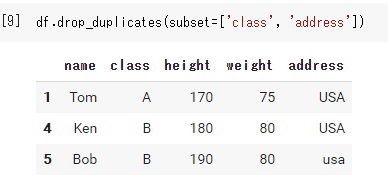
keepの役割
'first'(デフォルト):重複している最初の行を残す'last':重複している最後の行を残すFalse:重複している行すべて削除する
‘first’のときは上の画像(複数の列を削除)をになります。デフォルトなので引数には何も必要ありません。
’last’のとき
|
1 |
df.drop_duplicates(subset=['class', 'address'], keep='last') |
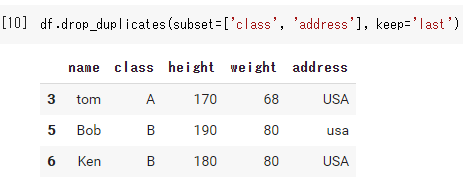
デフォルトのときと残ってる行が異なるのが分かります。
Falseのとき
|
1 |
df.drop_duplicates(subset=['class', 'address'], keep=False) |
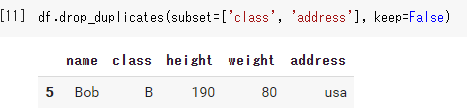
この場合、重複している行はすべて削除されるので注意してください。
ignore_indexの役割
Trueにするとindexを0から設定してくれます。
|
1 |
df.drop_duplicates(subset=['class', 'address'], ignore_index=True) |
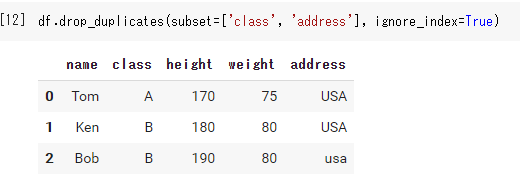
inplaceの役割
これは他のpandasの関数でもよく見る引数ですね。
- デフォルトでdrop_duplicates関数はもとのDataFrame(df)を変更しない。
inplace=True:もとのDataFrameごと変更できる。
デフォルト(False)のとき
|
1 2 |
df.drop_duplicates(subset=['class', 'address']) df |
Trueのとき
|
1 2 |
df.drop_duplicates(subset=['class', 'address'], inplace=True) df |
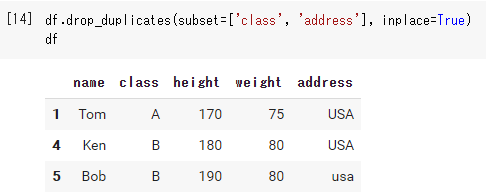
もし、重複を削除したはずなのに変更が反映されていないときは、このinplaceを確認してみてください。
ほかの変数に代入して(例えば、df1 = df.drop_duplicates(subset=['class', 'address']))もとのDataFrameも維持しながら変更を反映することも可能です。
まとめ
今回はデータフレームの重複した行を削除するdrop_duplicates関数を見ていきました。
ほかにも削除に使える関数をまとめてます。
こんにちは、今回はpandasのDataFrameで行や列を削除する方法を解説していきます。 それぞれの役割やメリットを確認しながら基本的なポイントを押さえていきましょう。 [itemlink post_id="4429"] […]