データ分析ではPythonのpandasが有名ですよね。とくに大量のデータを処理できるデータフレーム(DataFrame)は使いこなせると便利です。
そこで今回は、データフレームの作成方法を紹介していきたいと思います。


DataFrameとは?
行(raw)と列(column)からなる表のことです。Excelやスプレッドシートのようなものだと考えてください。MySQLなどでデータベースを扱ったことがあればそちらの方が近いですね。
行名(index / raw labels)や列名を自由に設定することができ、何万行もあるデータでも扱うことができます。
pandasを使うときは以下のようにインポートしておきましょう。以下に示すコードではこの続きに書いているものとします。
|
1 |
import pandas as pd |
ここで「as pd」とついているのは省略記号の意味です。「pansas.DataFrame」と書くところを「pd.Dataframe」と短縮して書くことができます。
「as」は「~として」という意味があるので「pandasをpdとして使う」ということです。
DataFrameの引数
|
1 |
pd.DataFrame(data, index, columns, dtype, copy) |
| 引数 | 内容 |
|---|---|
| data | 要素に入るデータを渡す。 |
| index | 行名のリストを渡す。 |
| columns | 列名のリストを渡す |
| dtype | 要素のデータ型に関する引数。別記事で解説 |
| copy | 別記事で解説 |
データを渡す方法には行や列を指定する方法やnumpyの2次元配列を渡す方法などがあります。以下で詳しく紹介しています。
indexやcolumnsを指定しない場合は、0から順番に整数が割り振られます。
DataFrameの作成方法
リストで要素を渡す
|
1 2 3 4 5 6 7 |
df1 = pd.DataFrame( data={'列1': [10, 20, 30, 40], '列2': [50, 60, 70, 80], '列3': ['a', 'b', 'c', 'd']} ) df1 |
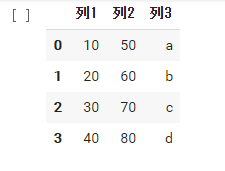
列名をキー、要素のリストをバリューにして渡しています。最もシンプルな方法だと思います。
この方法では、すべての列に同じ長さのリストを渡す必要があります。
numpy.arrayで要素を渡す
arrayとは配列のことで、数学の行列のようなものだとイメージしてください。
大学数学の線形代数で習います。
numpyとはそういった多次元行列計算を行えるライブラリーです。
1次元配列を使う
|
1 2 3 4 5 6 7 8 9 |
import numpy as np df2 = pd.DataFrame( data={'列1': np.array([10, 20, 30, 40]), '列2': np.array([50, 60, 70, 80]), '列3': np.array(['a', 'b', 'c', 'd'])} ) df2 |
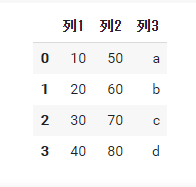
バリューにnumpyの1次元配列を渡しています。一般的に配列には数値を渡しますが、今回は「a,b,c,d」の文字でも試してみました。エラーにはならないですが違和感はあります(笑)
この方法でもすべての配列を同じ長さにする必要があります。
2次元配列を使う
|
1 2 3 4 5 6 7 8 |
df3 = pd.DataFrame( data=np.array([[10, 20, 30, 40], [11, 21, 31, 41], [12, 22, 32, 42]]), index=['行1', '行2', '行3'], columns=['列1', '列2', '列3', '列4'] ) df3 |
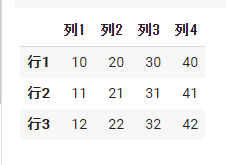
2次元配列の場合、行名(index)と列名(columns)を指定したほうが分かりやすいです。
もし、指定しない場合は0から順に整数が割り振られます。
この方法でも配列に含まれる各リストの大きさは同じにしておきましょう。
Seriesで要素を渡す
Seriesとは1次元の表です。Pythonのリストのようなものをイメージしてください。
もちろんリストよりデータ分析に関する操作性に優れています。
以下のように渡すことでDataFrameを作成することができます。
|
1 2 3 4 5 6 7 |
df4 = pd.DataFrame( data={'列1': pd.Series([10, 20, 30, 40]), '列2': pd.Series([50, 60, 70, 80]), '列3': pd.Series(['a', 'b', 'c', 'd'])} ) df4 |
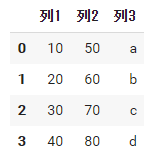
この方法では、各列のSeriesの大きさが異なっていても大丈夫です。
Seriesでは要素を入れるインデックスを指定することができます。
つまり、空のセルを作ることができます。
|
1 2 3 4 5 6 7 8 9 10 |
df5 = pd.DataFrame( data={'列1': pd.Series([10, 20, 30, 40], index=['行1', '行2', '行3', '行4']), '列2': pd.Series([50, 60, 80], index=['行1', '行2', '行4']), '列3': pd.Series(['b', 'c', 'd'], index=['行2', '行3', '行4'])} ) df5 |
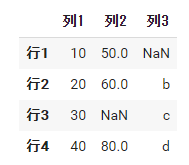
各列のSeriesのindexを指定します。DataFrameのindexではないので注意してください。
画像でNaNになっているところが空になっています。
1行ずつ辞書で作成する方法
列名をキー、要素をバリューにして、1行ずつ作成する方法です。
|
1 2 3 4 5 6 7 8 9 10 |
df6 = pd.DataFrame( data=[{'列1': 10, '列2': 50, '列3': 'a'}, #1行目 {'列1': 20, '列2': 60, '列3': 'b'}, #2行目 {'列1': 30, '列2': 70, '列3': 'c'}, #3行目 {'列1': 40, '列2': 80, '列3': 'd'}], #4行目 index=['行1', '行2', '行3', '行4'], ) df6 |
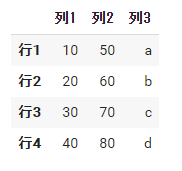
少々手間の書き方ですが、このように1行ずつ作成することもできます。
この方法でも辞書の大きさは同じにしておきましょう。
まとめ
今回はpandasのDataFrameを作成する方法に関して見ていきました。
たくさん方法があるので必要に応じで早い方法を使えるようにしておきたいですね。
特に、Seriesを使う方法では列の大きさが異なってもいいのでとても便利です。