pandasでcsvをDataFrameとして読み込めるととっても便利ですよね。
ですが、ただ読み込むだけでなく、indexや読み込む行列を指定したり、欠損値を処理したりいろんなことができるとなお便利です。
そこで、この記事では読み込みで使うread_csv関数の引数を目的別に解説していこうと思います。
ちなみに、csvとはcomma-separated values(カンマセパレーティッドバリュー)のことで、カンマで値を区切って書かれてたものになります。
このように、データを区切っている文字のことを「区切り文字」いいます。
ほかにも、タブ文字で区切ったり(tsv)スペース文字で区切ったり(ssv)セミコロン(;)を使っているものもあります。
以下のcsvファイルを使って開いてみます。
|
1 2 3 4 |
class,No,name,height A,1,山田,170.2 B,3,吉川,158.7 C,,佐藤,168.9 |
目次

read_csvの基本の引数
| 引数 | デフォルト値 | 意味 |
|---|---|---|
filepath_or_buffer | 必須引数 | csvのファイルパスやURLを渡します。 |
sep | ',' | 区切り文字を渡しますが、csvの読み込みなら変更する必要はありません。 |
delimiter | None | sepと同じです。必要ならsepを変更しましょう。sepとdelimiterの違い (英語) |
delim_whitespace | False | Trueで空白文字(「' '」「' '」など)を区切り文字にする。sep='\s+'と同じこと。 |
dtype | None | 整数(int)や小数(float)などのデータ型を指定できる。 dictで列ごとに個別に指定することも可能。 列にNaNがあるときint型は指定できない convertersが優先される。 |
converters | None | dictで特定の列の値を変換する関数を指定できる。 例: {'col1': lambda x: float(x)*2} で値を2倍にする。 |
encoding | None | 読み込むときの文字コードを指定する。 日本語を含むcsvなら 'utf_8'、'shift_jis'、'cp932'などが使える。 |
squeeze | False | Trueでcsvが一列だけのときSeriesを返す。 |
csvを読み込む方法
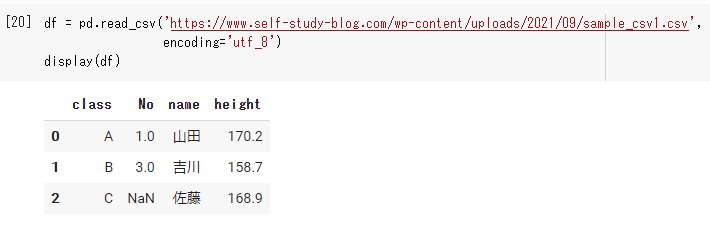
|
1 2 3 |
df = pd.read_csv('https://www.self-study-blog.com/wp-content/uploads/2021/09/sample_csv1.csv', encoding='utf_8') display(df) |
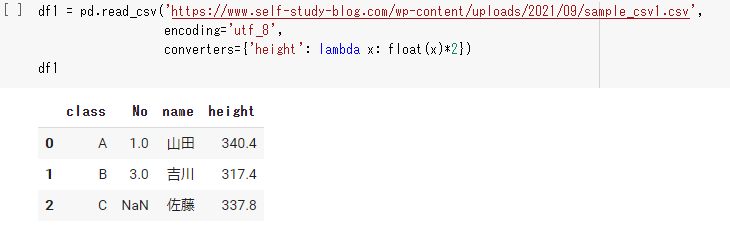
convertersとdtypeの違い
- 両方ともdictで渡す。辞書のキーには列名を使う。
- convertersは関数を使うこともできるので前処理に便利です。
- dtypeは列ごとのデータ型のみ設定可能
|
1 2 3 4 |
df1 = pd.read_csv('https://www.self-study-blog.com/wp-content/uploads/2021/09/sample_csv1.csv'', encoding='utf_8', converters={'height': lambda x: float(x)*2}) display(df1) |
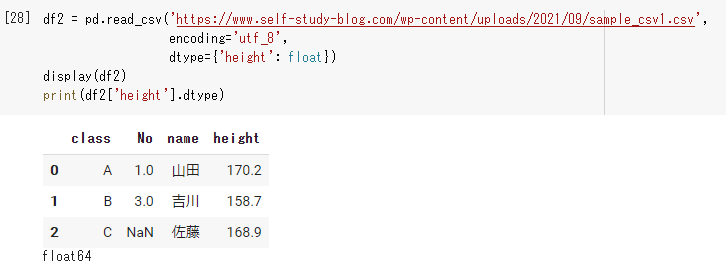
|
1 2 3 4 5 |
df2 = pd.read_csv('https://www.self-study-blog.com/wp-content/uploads/2021/09/sample_csv1.csv', encoding='utf_8', dtype={'height': float}) display(df2) print(df2['height'].dtype) |
インデックス・列名を指定・変更する方法
| 引数 | デフォルト値 | 意味 |
|---|---|---|
header | 'infer' | デフォルトではheader=0と同じくデータの1行をcolumnsとする。渡した整数の行をcolumnsとしてそれ以降の行を読み込む 整数のリストで渡すと複数行をcolumnsにできる |
names | NoDefault.no_default | リストを渡すとcolumnsを指定できる。列の数とリストの長さが異なってもエラーにならないので注意が必要。 |
index_col | None | indexにしたい列名を渡す。複数指定する場合はリストで渡す。 この引数を使用するとMultiindexになるので要注意 |
prefix | NoDefault.no_default | ヘッダーがない場合に列番号に追加するプレフィックス、 例えば、 prefix='X'のときの列名は、X0、X1、…となる。 |
mangle_dupe_cols | True | デフォルトで重複する列は、「X」…「X」ではなく、「X」、「X.1」、…「X.N」と指定される。 Falseを渡すと、列の名前が重複している場合、データが上書きされる。 |
|
1 2 3 4 |
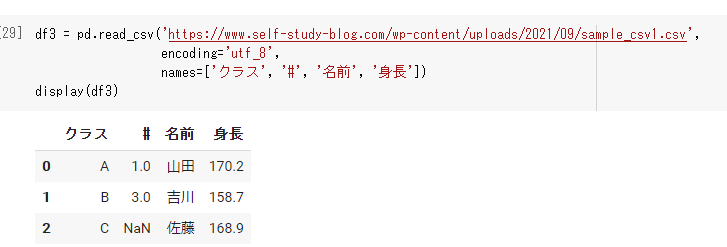
df3 = pd.read_csv('https://www.self-study-blog.com/wp-content/uploads/2021/09/sample_csv1.csv', encoding='utf_8', names=['クラス', '#', '名前', '身長']) display(df3) |
行列を指定して読み込む方法
| 引数 | デフォルト値 | 意味 |
|---|---|---|
usecols | None | 読み込みたいcolumns名をリストで渡す。 |
skiprows | None | 先頭からスキップしたい行数を整数でを渡す。 スキップしたい行番号を整数のリストで渡す。 ヘッダーがあるとき、ヘッダーが0行目になります。 |
skipfooter | 0 | スキップするファイル下部の行数を整数で渡す。 これを使うときは engine='python'にしないと警告が出る。 |
nrows | None | 読み込む行数を整数で渡す。大きいファイルの一部を読み込むときに有効。 |
skip_blank_lines | True | デフォルトで空白行をNaN値として解釈するのではなく、スキップします。 |
lineterminator | None | 改行記号を指定します。1文字の文字列しか指定できません。 |
on_bad_lines | ‘error’ | 不良行(フィールド数が多すぎる行)に遭遇した場合の処理を指定。'error':不正な行に遭遇した場合、例外を発生。(デフォルト)'warn':不正な行に遭遇した際に警告を発し、その行をスキップ。'skip':不正な行に遭遇しても警告を出さずにスキップ。 |
|
1 2 3 4 5 6 7 8 9 10 11 |
df4 = pd.read_csv('https://www.self-study-blog.com/wp-content/uploads/2021/09/sample_csv1.csv', encoding='utf_8', usecols=['name'], skiprows=[1], skipfooter=1) print(df4) #出力 name 0 吉川 |
空白・欠損(NaN)を削除・処理する方法
| 引数 | デフォルト値 | 意味 |
|---|---|---|
na_values | None | NA/NaNとして認識する文字列を渡す。複数指定する場合は文字列のリストを渡す。 dictでは列ごとにNA/NaNとして認識する文字列を指定できる。 |
keep_default_na | Ture | na_valuesが渡されたかどうかによって、動作が異なるが使わなくてもOK。na_filter=False のとき、keep_default_na と na_values は無視される |
na_filter | Ture | 欠損値マーカー(空の文字列とna_valuesの値)を検出します。 NAがないデータでは、 Falseで、大きなファイルを読み込む際のパフォーマンスが向上。 |
verbose | False | Trueで欠損値を処理する時間などが表示される。 |
|
1 2 3 4 5 |
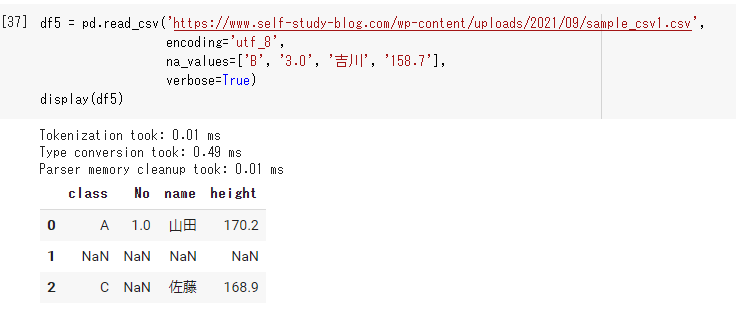
df5 = pd.read_csv('https://www.self-study-blog.com/wp-content/uploads/2021/09/sample_csv1.csv', encoding='utf_8', na_values=['B', '3.0', '吉川', '158.7'], verbose=True) display(df5) |
数値・文字列を指定・変更する方法
| 引数 | デフォルト値 | 意味 |
|---|---|---|
thousands | None | 桁区切り文字を指定できる。例えば','など。数値が桁区切り文字込みの文字列で与えられているとき(例: "123,456")thousands=',' とすると、123456と認識してくれる。データを区切るためのカンマと桁区切りを区別するためのもの。 |
decimal | '.' | 小数点として認識される文字(例:欧州のデータには「,」を使用) |
true_values | None | Trueとみなしたい値のリストを渡す。true_values=['Yes', 'yes', 'Ok']のときこれら3つはすべてTrueとして表示される。 |
false_values | None | Falseとみなしたい値のリストを渡す。 上と同じ使い方。 |
skipinitialspace | False | Trueで区切り文字の後のスペースをスキップします。 |
quotechar | ’”’ | 引用符を指定する。長さ1の文字列のみ指定可能。 引用符で囲まれた部分にカンマが含まれていても文字列として処理されます。 |
quoting | 0 | クォーテーションで囲まれた部分をどのように処理するかのモードを指定する。 モードに関する公式ページはコチラ 0:QUOTE_MINIMAL(デフォルト) → 「”」で囲まれた部分のみクォート扱い。 1:QUOTE_ALL → すべてをクォート扱い 2:QUOTE_NONNUMERIC → 数値以外はクォート扱い 3:QUOTE_NONE → クォートを無視してデータを区切る 特殊なデータでないなら変更しなくてOKだと思います。 |
doublequote | True | デフォルトで quotecharで指定した文字列が2つ連続したとき、文字列として扱ってくれる。 |
escapechar | None | quoting=3のときに、他の文字をエスケープするために使用される1文字の文字列。 |
comment | None | 長さ1の文字列を指定。その文字列以降は無視され、次の行へ移る。comment='#'のとき、#empty\na,b,c\n1,2,3は'a,b,c'がheaderとして扱われる。 |
encoding_errors | 'strict' | エンコーディングエラーの扱いを指定します。 エラーハンドラに関する公式ページはコチラ |
|
1 2 3 4 5 6 |
df6 = pd.read_csv('https://www.self-study-blog.com/wp-content/uploads/2021/09/sample_csv1.csv', encoding='utf_8', false_values=['C', '山田'], true_values=['A', 'B', '佐藤'], ) display(df6) |
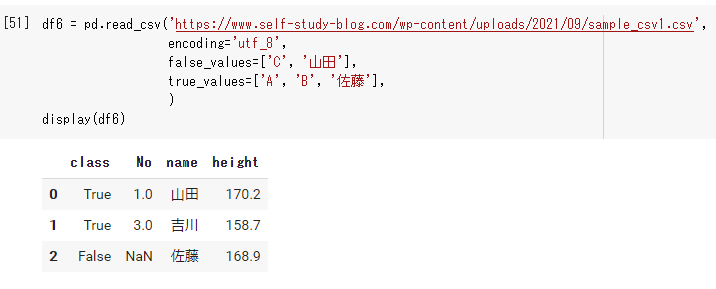
上の例でもあるように true_valuesと false_values は「山田」や「佐藤」などの日本語には反映されませんでした。
日付を指定・変更する方法
| 引数 | デフォルト値 | 意味 |
|---|---|---|
parse_dates | False | True:indexの解析 (indexが日付のときのみ機能します。) 列名のリスト:各列を日付データとして解析 列名のリストのリスト:結合して日付として解析 |
infer_datetime_format | False | Trueのときparse_datesも有効なら処理速度が向上する可能性がある。 |
keep_date_col | False | Trueのときparse_datesが複数列の結合を指定しているなら、元の列を削除しない。 |
date_parser | None | 日付データを処理する関数を渡す。あらかじめ関数を定義しておく必要あり。 |
dayfirst | False | Trueにすると、日ー年の順になっているデータも読み込める。 |
cache_dates | True | Trueなら一意に変換された日付のキャッシュを使用して、日付時間の変換を行う。 |
日付の設定に関しては以下の記事で詳しくまとめています。
関連記事
csvをDataFrameとして読み込むときに日付の処理ができると便利ですよね。 この記事では、Pythonのpandasでread_csv関数の日付に関する処理を紹介してきます。 ほかのread_csv関数の引数は以下の記事[…]

そのほかの引数
ここでは使用頻度が少なそうなものや、高度な設定をする引数を紹介します。
| 引数 | デフォルト値 | 意味 |
|---|---|---|
engine | None | 使用するパーサーエンジンを指定できる。'C':高速'python':機能的に充実 |
iterator | False | Trueでイテレート用のTextFileReaderオブジェクトを返す。 |
chunksize | None | 整数を渡すとその行数分のイテレート用のTextFileReaderオブジェクトを返す。 |
compression | 'infer' | 圧縮ファイルの解凍。デフォルトのままでの問題なく使える。‘gzip’、‘bz2’、‘zip’、 ‘xz’を指定可能 |
dialect | None | このパラメータを指定すると、delimiter、doublequote、escapechar、skipinitialspace、quotechar、quotingの各パラメータの値が上書きされる。たぶん使わないやつ。 |
error_bad_lines | None | バージョン1.3.0以降では非推奨 |
warn_bad_lines | None | バージョン1.3.0以降では非推奨 |
low_memory | True | 各列でデータ型が混在していないなら、Flaseにすると処理が減る。内部処理のこと |
memory_map | False | Trueにするとファイルパスへアクセスるときに速くなる。 |
float_precision | None | Cエンジンが浮動小数点値に使用するコンバータを指定。'high':通常のコンバータ'legacy':低精度のpandasオリジナルのコンバータ'round_trip':ラウンドトリップコンバータです。 |
storage_options | None | ホスト、ポート、ユーザー名、パスワードなどをdictで指定。HTTP(S)のURLの場合、キーと値のペアはヘッダーオプションとしてurllibに転送される。 |
まとめ
いかがでしたか?
pandasのread_csvの引数をすべてまとめてみました。
使わなさそうなものもありますが、日付や文字列、欠損の処理ができると便利ですよね。
csvの読み込みに役に立てば幸いです。